Projekt na (niejeden) weekend: Netbeans TOML plugin - podświetlanie błędów
...buch! Prawie rok od ostatniego wpisu. Czasem tak bywa, że nie ma na nic czasu. Czasem jakiś projekt nas wysysa, a po zakończeniu zostaje niesmak i trzeba odchorować... Np. jako odtrutkę można zaaplikować rozpoczęty kiedyś projekt obsługi Toml dla Netbeans i dopisać jakąś kolejną funkcję :)
Skoro mamy już kolorowanie składni, breadcrumbs i zwijanie kodu — można się przymierzyć do znajdowania i oznaczania
błędów składni.
Popraweczki
Zanim przejdę do właściwego tematu:
- zauważyłem, że z gramatyką jest
cośnie tak — czasami podkreślanie dziwnie działało/nie działało etc. Okazało się, że oryginalne repozytorium miało już poprawki, więc po prostu uaktualniłem gramatykę do najnowszej wersji - odbył się mały refactoring - moduł dostał własny pakiet
io.gitlab.ihsahn.netbeans.modules.toml, dodałem stałe naMIME_TYPEorazICON_PATH... etc
Podkreślanie błędów
Antlr error listener
Do parsowania używany biblioteki Antlr - jedną z jej cech jest fajna obsługa błędów podczas tokenizacji oraz parsowania - odpowiednio lexer oraz parser wykrywają błędy i raportują je do przekazanego listenera, jednocześnie same starają się jak najlepiej odnaleźć się w strukturze po wykryciu błędu i kontynuować swoją pracę.
Każdy taki listener musi implementować interfejs
ANTLRErrorListener. Oczywiście interfejs
posiada metody odpowiadające za różne problemy, w naszym przypadku tak naprawdę interesuje nas tylko syntaxError.
W związku z tym nasz własny listener będzie dziedziczył z BaseErrorListener,który implementuje wszystkie metody interfejsu (jako puste).
public class TomlAntlrErrorListener extends BaseErrorListener {
private final List<TomlSyntaxError> errors;
public TomlAntlrErrorListener(List<TomlSyntaxError> errors) {
this.errors = errors;
}
@Override
public void syntaxError(Recognizer<?, ?> recognizer, Object offendingSymbol, int line, int column,
String errorMessage, RecognitionException re) {
// special handling for lexer `no viable` exceptions becayse we do rewrite some of them
if (re instanceof LexerNoViableAltException) {
lexerNoViableAltException((TomlGrammarLexer) recognizer, errorMessage, (LexerNoViableAltException) re);
} else if (offendingSymbol instanceof CommonToken) {
CommonToken ct = (CommonToken) offendingSymbol;
if ((ct.getType() == -1) && (recognizer instanceof TomlGrammarParser)) {
errors.add(new TomlSyntaxError(errorMessage, ct.getStartIndex() - 1, ct.getStartIndex()));
} else {
errors.add(new TomlSyntaxError(errorMessage, ct.getStartIndex(), ct.getStartIndex() + ct.getText().length()));
}
}
}
private void lexerNoViableAltException(TomlGrammarLexer lexer, String errorMessage, LexerNoViableAltException noViableAltException) {
CharStream inputStream = lexer.getInputStream();
String errorDisplay = lexer.getErrorDisplay(inputStream.getText(
new Interval(noViableAltException.getStartIndex(), inputStream.index())));
//original message is "token recognition error at ", so let's rewrite it
if (errorDisplay != null && errorDisplay.startsWith("\"")) {
errors.add(new TomlSyntaxError("Unfinished double quoted string literal",
noViableAltException.getStartIndex(),
noViableAltException.getStartIndex() + errorDisplay.length()));
} else {
errors.add(new TomlSyntaxError(errorMessage,
noViableAltException.getStartIndex(),
noViableAltException.getStartIndex() + 1));
}
}
}
syntaxError podczas wywołania przez antlr dostaje następujące parametry:
recognizerparser lub lexer, który wykrył błądoffendingSymbol- jeśli recognizer jest parserem to symbol, który powoduje błądline- linia, w której występuje błądcolumn- kolumna, w której występuje błąderrorMessage- opis błędu wygenerowany przez antlrrejedna z klas dziedziczących po RecognitionException
W przypadku błędów pochodzących z lexera niektóre komunikaty mogą być... mało informujące. Stad dodatkowa obsługa
LexerNoViableAltException i nadpisanie
komunikatu błędu w przypadku problemu z brakiem zamknięcia " (pomysł zaczerpnięty z kodu parsera dla mysql)
Z pozostałych dziwolągów w kodzie:
if ((ct.getType() == -1) && (recognizer instanceof TomlGrammarParser)) {
to specjalna obsługa dla brakujących elementów na końcu pliku (inna logika wyliczania początku i końca występowania błędu)
Podpięcie pod parser i lexer
Tu nie ma żadnej filozofii:
- trzeba odpiąć domyślne error listenery (wypisujące blędy na konsole)
- zapiąć do lexera i parsera nasz nowy listener
- zebrane błędy gdzieś zapisać (w naszym przypadku w polu w klasie
TomlParserResult)
Odpowiednio zmieniona metoda z NetbeansTomlParser:
@Override
public void parse(Snapshot snapshot, Task task, SourceModificationEvent sourceModificationEvent) throws ParseException {
CharSequence text = snapshot.getText();
CharStream inp = new CharSequenceCharStream(text, text.length(), snapshot.getSource().getFileObject().getNameExt());
TomlGrammarLexer lexer = new TomlGrammarLexer(inp);
CommonTokenStream tokenStream = new CommonTokenStream(lexer);
TomlGrammarParser parser = new TomlGrammarParser(tokenStream);
// remove default listeners
parser.removeErrorListeners();
lexer.removeErrorListeners();
List<TomlSyntaxError> syntaxErrors = new LinkedList<>();
TomlAntlrErrorListener errorListener = new TomlAntlrErrorListener(syntaxErrors);
lexer.addErrorListener(errorListener);
parser.addErrorListener(errorListener);
TomlGrammarParser.DocumentContext document = parser.document();
lastResult = new TomlParserResult(snapshot, document, syntaxErrors);
}
Task i TaskFactory
Operacje działające na rezultatach parsingu (u nas TomlParserResult) powinny wykonywać się w tle.
W zależności od tego co dana operacja ma robić powinna powstać klasa dziedzicząca z ParserResultTask
oraz odpowiednia fabryka tworząca jej instancje (dziedzicząca z TaskFactory).
W naszym przypadku będzie to TomlSyntaxErrorHighlightingTaskFactory:
@MimeRegistration(mimeType=Constants.MIME_TYPE,service=TaskFactory.class)
public class TomlSyntaxErrorHighlightingTaskFactory extends TaskFactory {
@Override
public Collection<? extends SchedulerTask> create(Snapshot snpshot) {
return Collections.singleton(new TomlSyntaxErrorHighlightingTask());
}
}
Z @MimeRegistration korzystaliśmy już wcześniej,
poza tym nie ma tu prawie wcale logiki. Po zmianach w pliku Netbeans zawoła metodę create , która stworzy nasz nowy task podświetlający błędy.
Skoro o Task mowa:
public class TomlSyntaxErrorHighlightingTask extends ParserResultTask {
private boolean cancelled = false;
@Override
public void run(Parser.Result result, SchedulerEvent se) {
FileObject fileObject = result.getSnapshot().getSource().getFileObject();
TomlParserResult parserResult = (TomlParserResult) result;
List<ErrorDescription> errors = new ArrayList<>();
for (TomlSyntaxError syntaxError : parserResult.getSyntaxErrors()) {
if (cancelled) {
return;
}
errors.add(ErrorDescriptionFactory.createErrorDescription(Severity.ERROR,
syntaxError.getErrorMessage(), fileObject, syntaxError.getStartPosition(), syntaxError.getEndPosition()));
}
HintsController.setErrors(fileObject, "base-toml-parser", errors);
}
@Override
public int getPriority() {
return 100;
}
@Override
public Class<? extends Scheduler> getSchedulerClass() {
return Scheduler.EDITOR_SENSITIVE_TASK_SCHEDULER;
}
@Override
public void cancel() {
cancelled = true;
}
}
Oprócz bardzo podstawowych implementacji getPriority(), getSchedulerClass() i cancel() mamy
mięsko czyli run:
- wyciągamy
FileObject, do którego będziemy podpinać potem informacje o błędach - z rezultatu wyciągamy listę błędów i przepakowujemy ją w ErrorDescription
- gotową listę błędów "ustawiamy" na pliku poprzez HintsController.setErrors.
Tu ważny jest parametr
layer(u nas ma wartośćbase-toml-parser) - na danym pliku może operować wiele zadań rozpoznających różne problemy - każdy będzie miał swoją warstwę z błędami.
Klasy towarzyszące i inne zmiany
Do kompletu potrzebna nam klasa TomlSyntaxError - nie wklejam jej,
bo jest wybitnie prosta (trzy pola przechowywujące komunikat i pozycje w pliku), oraz jawna deklaracja
zależności na org-netbeans-spi-editor-hints w pom.xml.
Podsumowanie
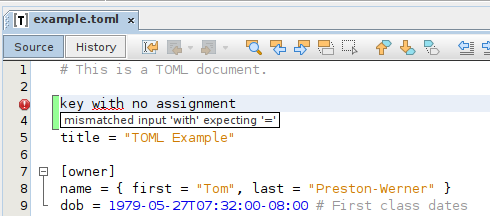
Efekt końcowy:
Repozytorium z aktualnym kodem: https://gitlab.com/ihsahn/netbeans-toml
Literatura
- The Definitive ANTLR 4 Reference książka o antlr (naprawdę dobra rzecz!)
- Api Antlr
- NetBeans api javadoc