Projekt na (niejeden) weekend: Netbeans TOML plugin - breadcrumbs
Pierwotny plan zakładał, że kolejnym etapem rozwoju wtyczki będzie "zwijanie" kodu. Zamiast tego mamyOkruszki chleba albo nawigacja okruszkowa jak to ładnie tłumaczy znaczenie breadcrumb nasza rodzima Wikipedia.
Czyli pasek pokazujący w hierarchicznej formie gdzie aktualnie znajdujemy się edytowanym dokumencie...
Spis wszystkich części wpisów z tej serii dostępny jest tutaj
Skaner struktury
Zarówno do zwijania kodu, jak i do breadcrumbs NetBeans wymaga "skanera" kodu — implementacji interfejsu
StructureScanner.
Jak widać z definicji, znajdują się tam dwie metody, obie przyjmujące parametr ParserResult - czyli do działania potrzeba też działającego Parsera.
Puste implementacje
Zacznę od wstawiania (pustych) implementacji dla:
- StructureScanner:
import org.netbeans.modules.csl.api.OffsetRange;
import org.netbeans.modules.csl.api.StructureItem;
import org.netbeans.modules.csl.api.StructureScanner;
import org.netbeans.modules.csl.spi.ParserResult;
import java.util.Collections;
import java.util.List;
import java.util.Map;
public class TomlStructureScanner implements StructureScanner {
@Override
public List<? extends StructureItem> scan(ParserResult parserResult) {
return Collections.emptyList();
}
@Override
public Map<String, List<OffsetRange>> folds(ParserResult parserResult) {
return Collections.emptyMap();
}
@Override
public Configuration getConfiguration() {
return null;
}
}
- ParserResult:
import org.netbeans.modules.csl.api.Error;
import org.netbeans.modules.csl.spi.ParserResult;
import org.netbeans.modules.parsing.api.Snapshot;
import java.util.Collections;
import java.util.List;
public class TomlParserResult extends ParserResult {
protected TomlParserResult(Snapshot snapshot) {
super(snapshot);
}
@Override
public List<? extends Error> getDiagnostics() {
return Collections.emptyList();
}
@Override
protected void invalidate() {
}
}
- Parser:
import org.netbeans.modules.parsing.api.Snapshot;
import org.netbeans.modules.parsing.api.Task;
import org.netbeans.modules.parsing.spi.ParseException;
import org.netbeans.modules.parsing.spi.Parser;
import org.netbeans.modules.parsing.spi.SourceModificationEvent;
import javax.swing.event.ChangeListener;
public class NetbeansTomlParser extends Parser {
private TomlParserResult lastResult;
@Override
public void parse(Snapshot snapshot, Task task, SourceModificationEvent sourceModificationEvent) throws ParseException {
lastResult = new TomlParserResult(snapshot);
}
@Override
public Result getResult(Task task) throws ParseException {
return lastResult;
}
@Override
public void addChangeListener(ChangeListener changeListener) {
}
@Override
public void removeChangeListener(ChangeListener changeListener) {
}
}
całość wpinam w TomlLanguage poprzez dodanie trzech metod:
@Override
public StructureScanner getStructureScanner() {
return new TomlStructureScanner();
}
@Override
public boolean hasStructureScanner() {
return true;
}
@Override
public Parser getParser() {
return new NetbeansTomlParser();
}
Do kompilacji potrzebne są jeszcze dodatkowe zależności (o czym informują nas stosowne komunikaty):
Project uses classes from transitive module org.netbeans.api:org-netbeans-modules-csl-types:jar:RELEASE112 which will not be accessible at runtime.
To fix the problem, add this module as direct dependency. For OSGi bundles that are supposed to be wrapped in NetBeans modules, use the useOSGiDependencies=false parameter
Project uses classes from transitive module org.netbeans.api:org-netbeans-modules-editor-lib:jar:RELEASE112 which will not be accessible at runtime.
To fix the problem, add this module as direct dependency. For OSGi bundles that are supposed to be wrapped in NetBeans modules, use the useOSGiDependencies=false parameter
Project uses classes from transitive module org.netbeans.api:org-netbeans-modules-parsing-api:jar:RELEASE112 which will not be accessible at runtime.
To fix the problem, add this module as direct dependency. For OSGi bundles that are supposed to be wrapped in NetBeans modules, use the useOSGiDependencies=false parameter
po dodaniu zależności...
<dependency>
<groupId>org.netbeans.api</groupId>
<artifactId>org-netbeans-modules-editor-lib</artifactId>
<version>${netbeans.version}</version>
</dependency>
<dependency>
<groupId>org.netbeans.api</groupId>
<artifactId>org-netbeans-modules-csl-types</artifactId>
<version>${netbeans.version}</version>
</dependency>
<dependency>
<groupId>org.netbeans.api</groupId>
<artifactId>org-netbeans-modules-parsing-api</artifactId>
<version>${netbeans.version}</version>
</dependency>
wszystko się kompiluje, chociaż oczywiście nie mamy jeszcze żadnej dodatkowej funkcjonalności.
Parser
Skoro StructureScanner przyjmuje jako parametr ParserResult to potrzeba nam działającej implementacji Parsera :)
Podobnie jak w przypadku lexera wykorzystam kod wygenerowany
przez ANTLR'a.
NetbeansTomlParser
Wynikiem działania Parsera z ANTLR jest obiekt reprezentujący główną regułę parsera zapisaną w gramatyce. W naszym przypadku document:
TomlGrammarParser.DocumentContext document = parser.document();
Obiekt parser to po prostu instancja wygenerowanej klasy TomlGrammarParser. Do jej utworzenia potrzebujemy klasy
implementującej TokenStream - idealnie do tego
nadaje się CommonTokenStream), który z kolei
jako parametr konstruktora przyjmuje poznany już wcześniej TomlGrammarLexer. Ostatni element układanki to adaptacja
wejściowego Snapshot
na CharStream , który przyjmuje lexer.
Nie będę się silił na wymyślanie koła na nowo, gotową klasę (CharSequenceCharStream) znalazłem tu.
public class NetbeansTomlParser extends Parser {
private TomlParserResult lastResult;
@Override
public void parse(Snapshot snapshot, Task task, SourceModificationEvent sourceModificationEvent) throws ParseException {
CharSequence text = snapshot.getText();
CharStream inp = new CharSequenceCharStream(text, text.length(), snapshot.getSource().getFileObject().getNameExt());
TomlGrammarLexer lexer = new TomlGrammarLexer(inp);
CommonTokenStream tokenStream = new CommonTokenStream(lexer);
TomlGrammarParser parser = new TomlGrammarParser(tokenStream);
parser.removeErrorListeners();
parser.setTrace(true);
TomlGrammarParser.DocumentContext document = parser.document();
lastResult = new TomlParserResult(snapshot, document);
}
@Override
public Result getResult(Task task) throws ParseException {
return lastResult;
}
@Override
public void addChangeListener(ChangeListener changeListener) {
}
@Override
public void removeChangeListener(ChangeListener changeListener) {
}
}
jak widać powyżej wynik parsowania przekazujemy również do rezultatu (TomlParserResult) - trzeba więc go zmienić,
aby przyjmował w konstruktorze (i przechowywał) obiekty typu TomlGrammarParser.DocumentContext.
Tworzenie struktury
Na tym etapie mam już sparsowany dokument (drzewo AST) w TomlParserResult. Chciałbym, żeby podstawowa struktura dokumentu
była dostępna bezpośrednio z rezultatu, np.: tak (fragment TomlStructureScanner):
@Override
public List<? extends StructureItem> scan(ParserResult parserResult) {
if (parserResult == null) {
return Collections.emptyList();
}
if (!(parserResult instanceof TomlParserResult)) {
Logger.getLogger(TomlStructureScanner.class.getName()).log(Level.WARNING, "parser result of unexpected type "+parserResult.getClass().getName());
return Collections.emptyList();
}
TomlParserResult tomlResult = (TomlParserResult) parserResult;
return tomlResult.getStructure();
}
czyli odpowiedzialność za dostarczenie struktury zrzuciłem na TomlParserResult...
Rzeczona metoda getStructure() wraz z metodą faktycznie przetwarzającą AST:
synchronized List<AbstractTomlStructureItem> getStructure() {
if (structure == null) {
structure = scanStructure();
}
return structure;
}
private List<AbstractTomlStructureItem> scanStructure() {
TomlStructureListener listener = new TomlStructureListener(getSnapshot().getSource().getFileObject().getName());
ParseTreeWalker.DEFAULT.walk(listener, context);
return Collections.singletonList(listener.getRoot());
}
Zakładam, że w przyszłości z tego samego rezultatu będzie korzystał algorytm "zwijający" bloki kodu, dlatego pobranie struktury
(oraz jej wytworzenie) jest synchronized a rezultat odkładany do wewnętrznego pola structure. Co do samego scanStructure():
wykorzystuję domyślnie generowany`Listener, który wraz z ParseTreeWalker umożliwia przejście po całej strukturze AST i
wywołanie odpowiednich metod dla danych elementów.
TomlStructureListener
ANTLR jest tak "miły", że podczas przetwarzania gramatyki generuje też klasy Listener'a
(zarówno interfejs, jak i pustą implementację). Mój TomlStructureListener będzie rozszerzał tę pustą implementację
(dzięki czemu moge przeciążyć tylko wybrane metody). Interfejs listenera zawiera odpowiednie metody "enter" i "exit" dla
każdego rodzaju wyrażenia zdefiniowanego w gramatyce. Mnie interesują tylko document (czyli "całość" pliku) i
table - czyli definicja pojedynczej tabeli.
Idąc (prawie) po kolei:
enterDocument:
@Override
public void enterDocument(TomlGrammarParser.DocumentContext ctx) {
root = new DocumentStructureItem(fileName, (long) ctx.start.getStartIndex());
super.enterDocument(ctx);
}
skoro dokument jest całością pliku, to zapisujemy go do (zwracanego potem jako
korzeń drzewa struktury) pola root.
enterTable:
@Override
public void enterTable(TomlGrammarParser.TableContext ctx) {
if (!nestedStructureItems.isEmpty()) {
while (!nestedStructureItems.isEmpty() && (!ctx.getText().startsWith(extractTextForMatching(nestedStructureItems.peekLast().getName())))) {
TableStructureItem item = nestedStructureItems.pollLast();
item.setEnd((long) (ctx.start.getStartIndex() - 1));
}
}
TableStructureItem item = new TableStructureItem(ctx.getText(), (long) ctx.start.getStartIndex());
if (!nestedStructureItems.isEmpty()) {
nestedStructureItems.peekLast().getChildren().add(item);
} else {
root.getChildren().add(item);
}
nestedStructureItems.add(item);
super.enterTable(ctx);
}
Tabele w dokumentach TOML moga być zagnieżdżone: np tabela [servers.env.test] jest "dzieckiem" [servers.env].
Narazie, na potrzeby wyświetlania breadcrubs przyjmuję, że ew zagnieżdżenie występuje, jeśli "dzieci" są
zadeklarowane w pliku bezpośrednio pod rodzicem. W przeciwnym przypadku zostanie dla nich utworzony osobny węzeł struktury.
Na końcu metody każdą nowo "rozpoczętą" tabelę (element struktury) odkładam na stos nestedStructureItems, żeby mogła ew
służyć jako rodzic dla następnych tabel. Dlatego przy wejściu do metody, sprawdzam czy nowa tabela jest dzieckiem
ostatniej na stosie (próbuje opróżniać stos, do czasu, aż będzie pusty albo aż początek nazwy nowej tabeli będzie odpowiadał
nazwie aktualnie ostatniej na stosie - wtedy znalazłem rodzica).
przy okazji
extractTextForMatchingto prosty subString (pozbywam się ostatniego ']') żeby można było użyćstartsWith()
"Ewentualny" rodzic (oraz jego rodzice) pozostają na stosie. Po stworzeniu nowego elementu struktury odpowiadającemu tabeli dodaję go jako dziecko: albo do ostatniego znalezionego "rodzica" (jeśli coś jest na stosie), albo elementu głównego.
exitDocument:
@Override
public void exitDocument(TomlGrammarParser.DocumentContext ctx) {
while (!nestedStructureItems.isEmpty()) {
TableStructureItem item = nestedStructureItems.pollLast();
item.setEnd((long) ctx.stop.getStopIndex());
}
root.setEnd((long) ctx.stop.getStopIndex());
super.exitDocument(ctx);
}
czyli zamknięcie całości pliku. Jeśli zostały nam jakieś "otwarte" tabele (wskutek zagnieżdżenia) to naturalnie
również jest to ich koniec. Dlatego wszystkim im, a także naszemu rootowi ustawiamy ten sam indeks zakończenia.
Elementy struktury
Klasy TableStructureItem oraz DocumentStructureItem są prostymi pochodnymi (nadpisanie typu ElementKind) klasy AbstractTomlStructureItem, która wygląda tak:
import org.netbeans.modules.csl.api.*;
import javax.swing.*;
import java.util.Collections;
import java.util.LinkedList;
import java.util.List;
import java.util.Set;
public class AbstractTomlStructureItem implements StructureItem {
private final String name;
private final Long start;
private Long end;
private final List<AbstractTomlStructureItem> children;
private final ElementKind elementKind;
public AbstractTomlStructureItem(String name, Long start, ElementKind elementKind) {
this.name = name;
this.start = start;
this.elementKind = elementKind;
this.end=start;
this.children = new LinkedList<>();
}
@Override
public String getName() {
return name;
}
@Override
public String getSortText() {
return name;
}
@Override
public String getHtml(HtmlFormatter htmlFormatter) {
return name;
}
@Override
public ElementHandle getElementHandle() {
return null;
}
@Override
public ElementKind getKind() {
return elementKind;
}
@Override
public Set<Modifier> getModifiers() {
return Collections.emptySet();
}
@Override
public boolean isLeaf() {
return getNestedItems().isEmpty();
}
@Override
public List<? extends StructureItem> getNestedItems() {
return children;
}
@Override
public long getPosition() {
return start;
}
@Override
public long getEndPosition() {
return end;
}
@Override
public ImageIcon getCustomIcon() {
return null;
}
public List<AbstractTomlStructureItem> getChildren() {
return children;
}
public void setEnd(Long end) {
this.end = end;
}
}
żadnych cudów: możliwie najprostsza implementacja interfejsu + dwie metody:
getChildren()(ułatwia dodawanie dzieci)setEnd()(ponieważ koniec bloku/tabeli nie jest znany podczas tworzenia obiektu).
Nawigacja
... kompilacja, uruchomienie i mamy breadcrubs! Widać, że podczas zmiany położenia kursora w dokumencie ich widok się
zmienia (i poprawnie pokazuje aktualne miejsce w strukturze), ale... no właśnie. Wybór elementu z breadcrums nie
przenosi nas w odpowiednie miejsce.
Za nawigację z breadcrumbs odpowiada metoda open() klasy StructureItemNode z modułu (NetBeans) csl.api:
public void open() {
ElementHandle elementHandle = item.getElementHandle();
FileObject file = elementHandle != null ? elementHandle.getFileObject() : null;
if (file != null) {
UiUtils.open(file, (int) item.getPosition());
}
}
...i zagadka od razu rozwiązana, nasz kod zwraca null zamiast ElementHandle. Zestaw funkcji ElementHandle częściowo pokrywa się z StructureItem dlatego AbstractTomlStructureItem będzie implementować także jego:
public class AbstractTomlStructureItem implements StructureItem, ElementHandle {
private final String name;
private final Long start;
private Long end;
private final List<AbstractTomlStructureItem> children;
private final ElementKind elementKind;
private final FileObject fileObject;
public AbstractTomlStructureItem(String name, Long start, ElementKind elementKind, FileObject fileObject) {
this.name = name;
this.start = start;
this.elementKind = elementKind;
this.end=start;
this.children = new LinkedList<>();
this.fileObject = fileObject;
}
@Override
public FileObject getFileObject() {
return fileObject;
}
@Override
public String getMimeType() {
return "application/toml";
}
@Override
public String getName() {
return name;
}
@Override
public String getIn() {
return null;
}
@Override
public String getSortText() {
return name;
}
@Override
public String getHtml(HtmlFormatter htmlFormatter) {
return name;
}
@Override
public ElementHandle getElementHandle() {
return this;
}
@Override
public ElementKind getKind() {
return elementKind;
}
@Override
public Set<Modifier> getModifiers() {
return Collections.emptySet();
}
@Override
public boolean signatureEquals(ElementHandle elementHandle) {
if (elementHandle instanceof AbstractTomlStructureItem) {
return name.equals(((AbstractTomlStructureItem)elementHandle).name);
}
return false;
}
@Override
public OffsetRange getOffsetRange(ParserResult parserResult) {
return null;
}
@Override
public boolean isLeaf() {
return getNestedItems().isEmpty();
}
@Override
public List<? extends StructureItem> getNestedItems() {
return children;
}
@Override
public long getPosition() {
return start;
}
@Override
public long getEndPosition() {
return end;
}
@Override
public ImageIcon getCustomIcon() {
return null;
}
public List<AbstractTomlStructureItem> getChildren() {
return children;
}
public void setEnd(Long end) {
this.end = end;
}
}
Oczywiście trzeba dostosować klasy pochodne (DocumentStructureItem oraz TableStructureItem) oraz TomlStructureListener żeby również przyjmowały dodatkowy parametr typu FileObject.
Uwagi na koniec
- nie znalazłem nigdzie opublikowanych javadoc dla
Common Scripting Api(csl.api), a to, co jest dostępne w kodzie jest zdecydowanie niewystarczające...
Podsumowanie
Efekt końcowy:
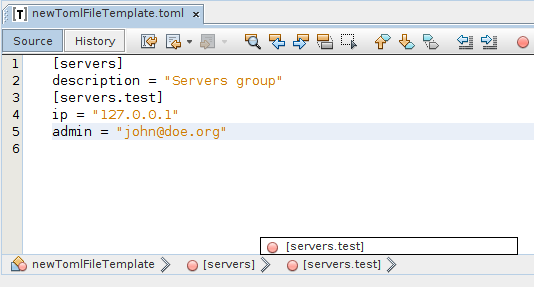
Repozytorium z aktualnym kodem: https://gitlab.com/ihsahn/netbeans-toml
Literatura
- Tom's Obvious, Minimal Language. oficjalne repo Toml
- Rich Client Programming: Plugging Into the NetBeans Platform książka o programowaniu z wykorzystaniem platformy Netbeans
- NetBeans api javadoc
- Seria artykułów na temat wykorzystania ANTLR w Netbeans
org.netbeans.modules.csl.api.StructureScannerna blogu Geertjan'a Wielenga