Projekt na (niejeden) weekend: Netbeans TOML plugin - kolorowanie składni
Poprzednim razem udało mi się stworzyć kod, który rozpoznaje pliki Tom's Obvious, Minimal Language., jest w stanie stworzyć nowy plik tego typu z szablonu, oraz zawiera podstawową konfigurację kolorów (wraz z rozróżnianiem znaków drukowalnych i odstępów). Pora dodać prawdziwe kolorowanie składni.
Własny lexer
Do pełnego kolorowania składni potrzebny będzie lexer z prawdziwego zdarzenia — taki, który naprawdę będzie rozumieć składnię TOML. Oczywiście można naklepać kod samemu, ale po co, skoro są do tego gotowe narzędzia? Netbeans posiada już biblioteki do dwóch najpopularniejszych generatorów parserów: zarówno do JavaCC jak i ANTLR. Z racji wcześniejszego doświadczenia z ANTLR oraz faktu, że w jego repozytorium jest już gotowa gramatyka, spróbuję wykorzystać ten właśnie generator.
Zmiany w pom.xml, gramatyka, generowanie kodu
- Po pierwsze potrzebujemy bibliotek, które są wymagane przez wygenerowany z ANTLR kod:
<dependency>
<groupId>org.netbeans.api</groupId>
<artifactId>org-netbeans-libs-antlr4-runtime</artifactId>
<version>${netbeans.version}</version>
</dependency>
-
Po drugie: plik z gramatyką: w
src/maintrzeba zrobić podkatalogantlr4i dodać plik gramatyki. Struktura katalogów, w której znajduje się gramatyka zostanie potem zamieniona na pakiet javy wygenerowanego kodu. Nazwa pliku gramatyki (oraz nazwa wykorzystana w pierwszej linii jakogramar) wykorzystywana jest jako wzorzec nazywania generowanych plików. Ponieważ chcę, aby nazwy plików rozpoczynały się od dużej litery, a zarazem chcę uniknąć konfliktów z wcześniej stworzonymi plikami Toml* zmienię nazwę gramatyki nagrammar TomlGrammar;i nazwę pliku naTomlGrammar.g4. -
Generowanie kodu:
<plugin>
<groupId>org.antlr</groupId>
<artifactId>antlr4-maven-plugin</artifactId>
<version>4.5.3</version>
<executions>
<execution>
<goals>
<goal>antlr4</goal>
</goals>
</execution>
</executions>
</plugin>
- Powyższe zmiany wystarczą, żeby maven zawołał wtyczkę antlr i na podstawie pliku z gramatyką wygenerował odpowiedni
kod i zasoby. Niestety ten sam maven nie jest na tyle inteligentny, żeby dołączyć dopiero-co wygenerowane zasoby do archiwum wyjściowego. Do pomocy wzywam więc
build-helper-maven-plugin:
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>build-helper-maven-plugin</artifactId>
<version>3.0.0</version>
<executions>
<execution>
<phase>generate-resources</phase>
<goals>
<goal>add-resource</goal>
</goals>
<configuration>
<resources>
<resource>
<directory>${project.build.directory}/generated-sources/antlr4</directory>
</resource>
</resources>
</configuration>
</execution>
</executions>
</plugin>
Zmiany w kodzie
TomlTokenId.java
Do tej pory rozpoznawaliśmy tylko znaki drukowane i odstępy. Teraz lista znanych tokenów powstaje jako wynik
przetwarzania gramatyki przez ANTLR i jest zapisywana do pliku *.tokens.
Muszę więc wcześniejszy enum zastąpić klasą, która umożliwi ustawianie wartości na podstawie tego pliku:
import org.netbeans.api.lexer.TokenId;
public class TomlTokenId implements TokenId {
private final String name;
private final String primaryCategory;
private final int id;
public TomlTokenId(String name, String primaryCategory, int id) {
this.name = name;
this.primaryCategory = primaryCategory;
this.id = id;
}
@Override
public String name() {
return name;
}
@Override
public int ordinal() {
return id;
}
@Override
public String primaryCategory() {
return primaryCategory;
}
}
ANTLRTokenReader
Konsekwencją powyższych zmian jest także to, że zamiast dotychczasowej stałej listy tokenów w TomlLanguageHierarchy
trzeba umożliwić jej inicjalizację na podstawie wcześniej wspomnianego pliku. Kod wczytujący listę tokenów z wygenerowanego pliku
pożyczam od James Reid'a:
package io.gitlab.ihsahn.netbeans.editor;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.HashMap;
import java.util.Map;
import org.openide.util.Exceptions;
/**
* @author James Reid
*/
public class AntlrTokenReader {
private final HashMap<String, String> tokenTypes = new HashMap<>();
public AntlrTokenReader() {
init();
}
/**
* Initializes the map
*/
private void init() {
tokenTypes.put("COMMENT", TokenCategories.comment.name());
tokenTypes.put("BOOLEAN", TokenCategories.bool.name());
tokenTypes.put("UNQUOTED_KEY", TokenCategories.keys.name());
tokenTypes.put("OFFSET_DATE_TIME", TokenCategories.date.name());
tokenTypes.put("LOCAL_DATE_TIME", TokenCategories.date.name());
tokenTypes.put("LOCAL_DATE", TokenCategories.date.name());
tokenTypes.put("LOCAL_TIME", TokenCategories.date.name());
tokenTypes.put("'{'", TokenCategories.braces.name());
tokenTypes.put("'}'", TokenCategories.braces.name());
tokenTypes.put("'[['", TokenCategories.brackets.name());
tokenTypes.put("']]'", TokenCategories.brackets.name());
tokenTypes.put("'['", TokenCategories.brackets.name());
tokenTypes.put("']'", TokenCategories.brackets.name());
tokenTypes.put("FLOAT", TokenCategories.number.name());
tokenTypes.put("INF", TokenCategories.number.name());
tokenTypes.put("NAN", TokenCategories.number.name());
tokenTypes.put("DEC_INT", TokenCategories.number.name());
tokenTypes.put("HEX_INT", TokenCategories.number.name());
tokenTypes.put("OCT_INT", TokenCategories.number.name());
tokenTypes.put("BIN_INT", TokenCategories.number.name());
tokenTypes.put("BASIC_STRING", TokenCategories.string.name());
tokenTypes.put("ML_BASIC_STRING", TokenCategories.string.name());
tokenTypes.put("LITERAL_STRING", TokenCategories.string.name());
tokenTypes.put("ML_LITERAL_STRING", TokenCategories.string.name());
tokenTypes.put("'='", TokenCategories.assignment.name());
tokenTypes.put("'.'", TokenCategories.dot.name());
}
/**
* Reads the token file from the ANTLR parser and generates
* appropriate tokens.
*
* @return
*/
public Map<Integer, TomlTokenId> readTokenFile() {
ClassLoader classLoader = Thread.currentThread().getContextClassLoader();
InputStream inp = classLoader.getResourceAsStream("TomlGrammar.tokens");
BufferedReader input = new BufferedReader(new InputStreamReader(inp));
return readTokenFile(input);
}
/**
* Reads in the token file.
*
* @param buff
*/
private Map<Integer, TomlTokenId> readTokenFile(BufferedReader buff) {
Map<Integer, TomlTokenId> tokenMap = new HashMap<>();
String line;
try {
while ((line = buff.readLine()) != null) {
int pos = line.lastIndexOf("=");
String name = line.substring(0, pos);
int tok = Integer.parseInt(line.substring(pos + 1));
TomlTokenId id;
String tokenCategory = tokenTypes.get(name);
if (tokenCategory != null) {
//if the value exists, put it in the correct category
id = new TomlTokenId(name, tokenCategory, tok);
} else {
//if we don't recognize the token, consider it to a separator
id = new TomlTokenId(name, "separator", tok);
}
//prevents duplicates
tokenMap.put(tok, id);
}
} catch (IOException ex) {
Exceptions.printStackTrace(ex);
}
return tokenMap;
}
enum TokenCategories {
bool, comment, date, keys, number, braces, brackets, string, assignment, dot
}
}
Oprócz metody wczytującej tokeny (readTokenFile) jest tu także definicja nazw kategorii (enum TokenCategories) oraz
przypisanie tokenów do tych kategorii (metoda init).
Niestety o ile ANTLR jest w stanie nam wygenerować listę tokenów, nie potrafi sam jej
skategoryzować (tym bardziej, że potrzebujemy potem nazw tych kategorii, żeby skonfigurować kolorowanie składni).
TomlLanguageHierarchy
TomlLanguageHierarchy powinno umożliwić wczytanie listy tokenów podczas pierwszego użycia, zmienia się w związku z tym metoda createTokenIds():
package io.gitlab.ihsahn.netbeans.editor;
import java.util.Collection;
import java.util.Map;
import org.netbeans.spi.lexer.LanguageHierarchy;
import org.netbeans.spi.lexer.Lexer;
import org.netbeans.spi.lexer.LexerRestartInfo;
public class TomlLanguageHierarchy extends LanguageHierarchy<TomlTokenId> {
private static Collection<TomlTokenId> tokens;
private static Map<Integer, TomlTokenId> idToToken;
static synchronized TomlTokenId getToken(int id) {
if (idToToken == null) {
init();
}
return idToToken.get(id);
}
private static void init() {
AntlrTokenReader reader = new AntlrTokenReader();
idToToken = reader.readTokenFile();
tokens = idToToken.values();
}
@Override
protected synchronized Collection<TomlTokenId> createTokenIds() {
if (tokens == null) {
init();
}
return tokens;
}
@Override
protected Lexer<TomlTokenId> createLexer(LexerRestartInfo<TomlTokenId> info) {
return new NetbeansTomlLexer(info);
}
@Override
protected String mimeType() {
return "application/toml";
}
}
Dodatkowo:
- pojawia się nowa metoda
getToken(int id), potrzebna do tłumaczenia tokenów z kodów ANTLR (w końcu tego używa wygenerowany Lexer) naTomlTokenId - zmienia się lexer na
NetbeansTomlLexer
NetbeansTomlLexer
Nowy lexer to tak naprawdę w głównej mierze przelotka tłumacząca tokeny z systemu ANTLR na TomlTokenId - patrz metoda: nextToken():
package io.gitlab.ihsahn.netbeans.editor;
import io.gitlab.ihsahn.netbeans.editor.antlr.TomlGrammarLexer;
import org.netbeans.api.lexer.Token;
import org.netbeans.spi.lexer.Lexer;
import org.netbeans.spi.lexer.LexerInput;
import org.netbeans.spi.lexer.LexerRestartInfo;
import org.netbeans.spi.lexer.TokenFactory;
public class NetbeansTomlLexer implements Lexer<TomlTokenId> {
private final LexerInput input;
private final TokenFactory<TomlTokenId> tokenFactory;
TomlGrammarLexer lexer;
public NetbeansTomlLexer(LexerRestartInfo<TomlTokenId> info) {
this.input = info.input();
NbLexerCharStream charStream = new NbLexerCharStream(input);
this.tokenFactory = info.tokenFactory();
this.lexer = new TomlGrammarLexer(charStream);
}
@Override
public org.netbeans.api.lexer.Token<TomlTokenId> nextToken() {
org.antlr.v4.runtime.Token token = lexer.nextToken();
Token<TomlTokenId> createdToken = null;
if (token.getType() != -1) {
TomlTokenId tokenId = TomlLanguageHierarchy.getToken(token.getType());
createdToken = tokenFactory.createToken(tokenId);
} else if (input.readLength() > 0) {
TomlTokenId tokenId = TomlLanguageHierarchy.getToken(TomlGrammarLexer.WS);
createdToken = tokenFactory.createToken(tokenId);
}
return createdToken;
}
@Override
public Object state() {
return null; //no specific state
}
@Override
public void release() {
//nothing to release
}
}
Jedyna niedogodność to fakt, że wygenerowany TomlGrammarLexer operuje na pochodnych CharStream, potrzeba więc jeszcze jednej klasy, która zaadaptuje LexerInput do wymaganego interfejsu.
NbLexerCharStream
... czyli rzeczony adapter. Nie będę tu opisywał tej klasy, bo pożyczyłem ją z kodu Netbeans.
Co ciekawe w kodzie Netbeans znalazłem dwa bliźniacze pliki:
Oba nieznacznie się różnią, ale oba mają ten sam błąd podczas usuwania danych ze stosu markers:
for(int i = marker; i < markers.size(); i++) {
markers.remove(i);
}
całość najprawdopodobniej niegroźna (ponieważ kontrakt zdefiniowany jest tak, że zwalnianie markerów ma być zawsze po kolei, w odwrotnej kolejności), ale dla porządku zgłosiłem PR z poprawką. U siebie wyłączam w ogóle funkcjonalność markerów (zakładam, że jest ciągły dostęp do całego bufora z zawartością pliku).
Konfiguracja kolorów
Na koniec pozostaje zmienić definicje w TomlDefaultFontsAndColors.xml (oraz uzupełnić tłumaczenia w Bundle.properties):
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE fontscolors PUBLIC "-//NetBeans//DTD Editor Fonts and Colors settings 1.1//EN"
"http://www.netbeans.org/dtds/EditorFontsColors-1_1.dtd">
<fontscolors>
<fontcolor name="brackets" default="separator"/>
<fontcolor name="braces" default="separator"/>
<fontcolor name="comment" default="comment"/>
<fontcolor name="bool" default="keyword"/>
<fontcolor name="keys" default="identifier"/>
<fontcolor name="date" default="keyword"/>
<fontcolor name="number" default="number"/>
<fontcolor name="string" default="string"/>
<fontcolor name="assignment" default="operator"/>
<fontcolor name="dot" default="operator"/>
<fontcolor name="whitespace" default="whitespace"/>
</fontscolors>
Dla każdej kategorii jest osobny wpis. Tym razem zrezygnowałem ze specyfikowania kolorów w domyślnej konfiguracji, za to ustawiłem kategorie, z których domyślnie powinny się brać kolory. W ten sposób, jeśli użytkownik ich nie zmieni, to bez względu na to, jaki profil kolorów wybierze, schemat kolorów powinien pasować do reszty IDE.
Uwagi na koniec
- myślę, że takie rzeczy jak
AntlrTokenReader(bez definicji kategorii),NbLexerCharStreammogłyby spokojnie się znaleźć w macierzystym repozytorium NetBeans jako api publiczne. Uprościłoby to tworzenie nowych wtyczek opartych o ANTLR. - trzeba uważać podczas definiowania kolorów w plikach xml (np
TomlDefaultFontsAndColors.xml) - literówka w nazwie koloru powoduje trudne do zdiagnozowania błędy pojawiające się dopiero podczas pracy wtyczki.
Podsumowanie
Efekt końcowy:
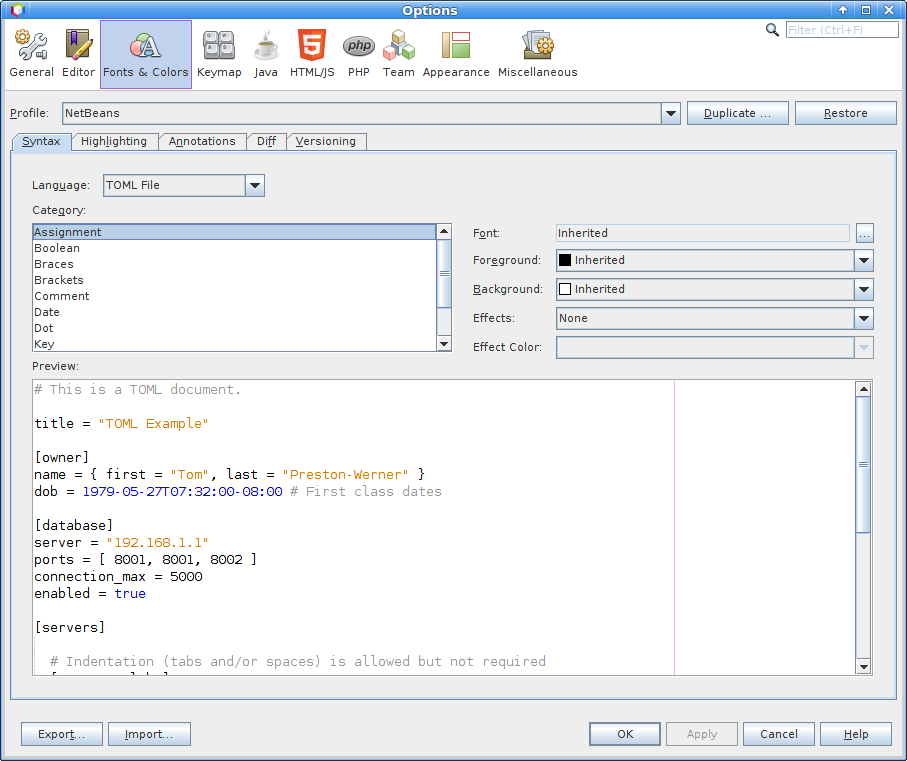
Repozytorium z aktualnym kodem: https://gitlab.com/ihsahn/netbeans-toml
Literatura
- Tom's Obvious, Minimal Language. oficjalne repo Toml
- Rich Client Programming: Plugging Into the NetBeans Platform książka o programowaniu z wykorzystaniem platformy Netbeans
- NetBeans api javadoc
- Seria artykułów na temat wykorzystania ANTLR w Netbeans
- Using an ANTLR Lexer For Syntax Coloring Tutorial